自编码器
自编码器
自编码器(auto-encoder, AE) 是通过无监督的方式来学习一组数据的有效编码(或表示)。
假设有一组$d$维的样本$\boldsymbol{x}^{(n)} \in \mathbb{R}^{d}, 1 \leqslant n \leqslant N$,自编码器将这组数据映射到$p$维的特征空间得到每个样本的编码$\boldsymbol{z}^{(n)} \in \mathbb{R}^{p}, 1 \leqslant n \leqslant N$,并且希望这组编码可以重构出原来的样本。自编码器的结构可分为两部分:
编码器(encoder):$f:\mathbb R^d \rightarrow \mathbb R^p$;
解码器(decoder):$g:\mathbb R^p \rightarrow \mathbb R^d$。
$$ \begin{aligned} \mathcal{L} &=\sum_{n=1}^{N}\|\boldsymbol{x}^{(n)}-g(f(\boldsymbol{x}^{(n)}))\|^{2} \\ &=\sum_{n=1}^{N}\|\boldsymbol{x}^{(n)}-f \circ g(\boldsymbol{x}^{(n)})\|^{2} \end{aligned} $$如果特征空间的维度$p$小于原始空间的维度$d$,自编码器相当于是一种降维或特征抽取方法。如果$p \geqslant d$,一定可以找到一组或多组解使得$f \circ g$为单位函数(identity function)$I(x)=x$,并使得重构错误为0。然而,这样的解并没有太多的意义。但是,如果再加上一些附加的约束,就可以得到一些有意义的解,比如编码的稀疏性、取值范围,$f$和$g$的具体形式等。如果我们让编码只能取个$k$不同的值($k < N$),那么自编码器就成为一个$k$类的聚类问题。
最简单的自编码器是如下图所示的两层神经网络。输入层到隐藏层用来编码,隐藏层到输出层用来解码,层与层之间互相全连接。
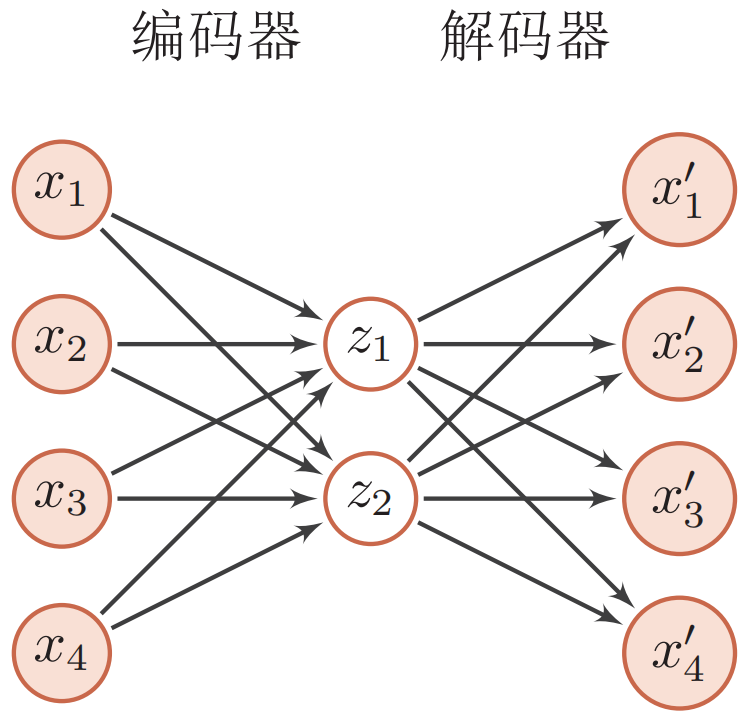
我们使用自编码器是为了得到有效的数据表示,因此在训练结束后,一般会去掉解码器,只保留编码器。编码器的输出可以直接作为后续机器学习模型的输入。
稀疏自编码器
自编码器除了可以学习低维编码之外,也能够学习高维的稀疏编码。假设中间隐藏层$\boldsymbol z$的维度$p$大于输入样本$\boldsymbol x$的维度$d$,并且让$\boldsymbol z$尽量系数,这就是稀疏自编码器(sparse auto-encoder, SAE)。稀疏自编码器的优点是有很高的可解释性,并同时进行了隐式的特征选择。通过给自编码器中隐藏层单元$\boldsymbol z$加上稀疏性限制,自编码器可以学习到数据中一些有用的结构。给定$N$个训练样本${\boldsymbol{x}^{(n)}}_{n=1}^{N}$,稀疏自编码器的目标函数为:
$$ \mathcal{L}=\sum_{n=1}^{N} \| \boldsymbol{x}^{(n)}-\boldsymbol{x}^{\prime (n)}\|^{2}+\eta \rho(Z)+\lambda\| W \|^{2} $$其中$Z=[\boldsymbol{z}^{(1)}, \cdots, \boldsymbol{z}^{(N)}]$表示所有训练样本的编码,$\rho(Z)$为稀疏性度量函数,$W$表示自编码器中的参数。$\rho(Z)$可以定义为一组训练样本中每一个神经元激活的概率。
$$ \hat{\rho}_{j}=\frac{1}{N} \sum_{n=1}^{N} z_{j}^{(n)} $$$$\hat{\rho}_{j}$$$$ \mathrm{KL}(\rho^{*} \| \hat{\rho}_{j})=\rho^{*} \log \frac{\rho^{*}}{\hat{\rho}_{j}}+(1-\rho^{*}) \log \frac{1-\rho^{*}}{1-\hat{\rho}_{j}} $$如果量$\hat{\rho}{j}=\rho^$,则$\mathrm{KL}(\rho^{} | \hat{\rho}{j})=0$。
$$ \rho(Z)=\sum_{j=1}^{p} \mathrm{KL}(\rho^{*} \| \hat{\rho}_{j}) $$堆叠自编码器
对于很多数据来说,仅使用两层神经网络的自编码器还不足以获取一种好的数据表示。为了获取更好的数据表示,我们可以使用更深层的神经网络。深层神经网络作为自编码器提取的数据表示一般会更加抽象,能够更好地捕捉到数据的语义信息。在实践中经常使用逐层堆叠的方式来训练一个深层的自编码器,称为堆叠自编码器(stacked auto-encoder, SAE)。堆叠自编码器一般可以采用**逐层训练(layer-wise training)**来学习网络参数。
降噪自编码器
我们使用自编码器是为了得到有效的数据表示,而有效的数据表示除了具有最小重构错误或稀疏性等性质之外,还可以要求其具备其它性质,比如对数据部分损坏(partial destruction) 的鲁棒性。高维数据(比如图像)一般都具有一定的信息冗余,比如我们可以根据一张部分破损的图像联想出其完整内容。因此,我们希望自编码器也能够从部分损坏的数据中得到有效的数据表示,并能够恢复出完整的原始信息。
降噪自编码器(denoising auto-encoder, DAE) 就是一种通过引入噪声来增加编码鲁棒性的自编码器。对于一个向量$\boldsymbol x$,我们首先根据一个比例$\mu$随机将$\boldsymbol x$的一些维度的值设置为0,得到一个被损坏的向量$\tilde{\boldsymbol{x}}$。然后将被损坏的向量$\tilde{\boldsymbol{x}}$输入给自编码器得到编码$\boldsymbol z$,并重构出原始的无损输入$\boldsymbol x$。
下图给出了自编码器和降噪自编码器的对比图:
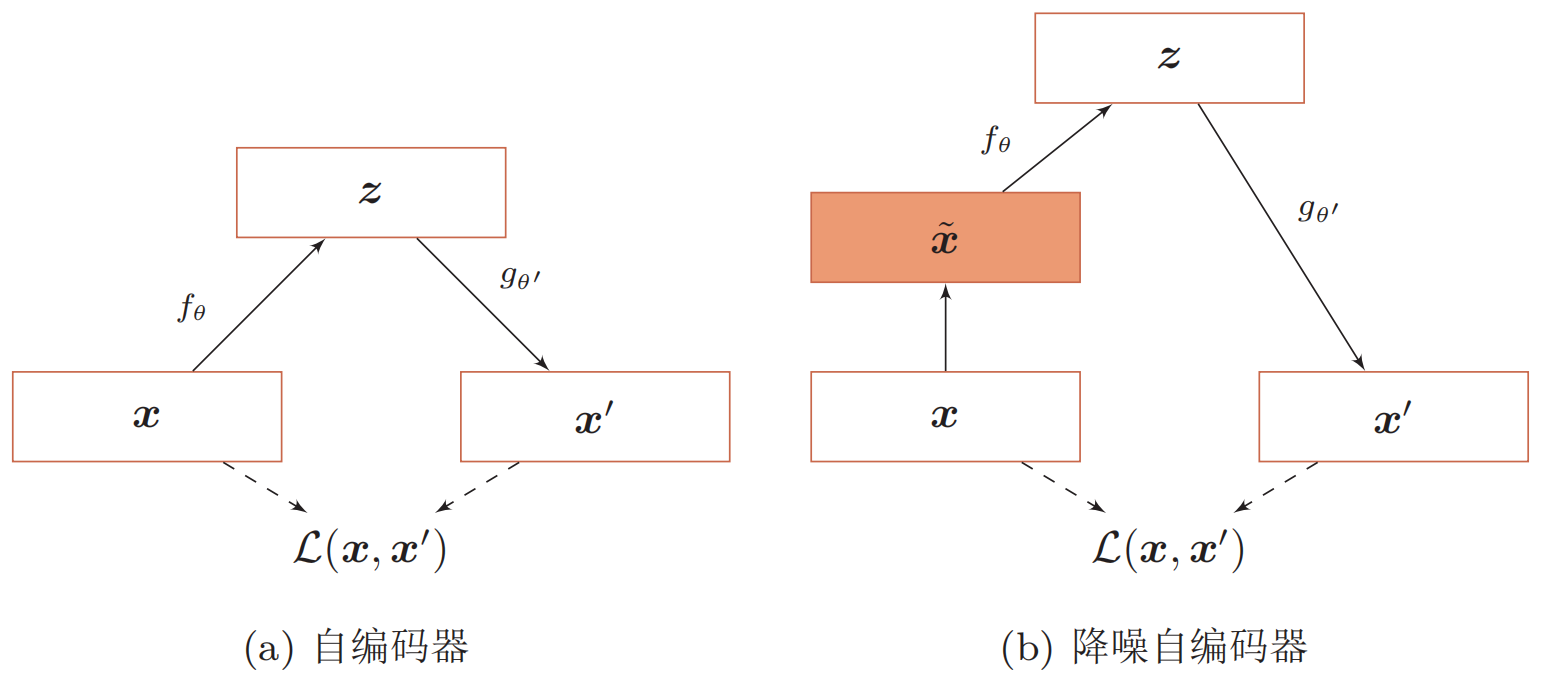
降噪自编码器的思想十分简单,通过引入噪声来学习更鲁棒性的数据编码,并提高模型的泛化能力。
Tensroflow实现自编码器完成光谱数据的降维与重构
import tensorflow as tf
import scipy.io as sio
import numpy as np
import matplotlib.pyplot as plt
# 数据获取,需要将数据导入当前目录
# A F K M类恒星数据各6000条
X_a = sio.loadmat('spectra_data\A.mat')['P1']
X_f = sio.loadmat('spectra_data\F.mat')['P1']
X_k = sio.loadmat('spectra_data\K.mat')['P1']
X_m = sio.loadmat('spectra_data\M.mat')['P1']
X_label = ['A', 'F', 'K', 'M']
X = np.vstack((X_a, X_f, X_k, X_m))
# 数据归一化
for i in range(X.shape[0]):
X[i] -= np.min(X[i])
if np.max(X[i]) != 0:
X[i] /= np.max(X[i])
print('Data shape: ', X.shape)
# 转为tf.data.Dataset格式
data = tf.data.Dataset.from_tensor_slices(X).shuffle(24000).batch(64, drop_remainder=True)
print(data)
# 定义自编码器模型
class AutoEncoder(tf.keras.Model):
def __init__(self):
super(AutoEncoder, self).__init__()
self.encoder_1 = tf.keras.layers.Dense(64)
self.encoder_2 = tf.keras.layers.Dense(10)
self.decoder_1 = tf.keras.layers.Dense(64)
self.decoder_2 = tf.keras.layers.Dense(3522)
def call(self, x):
x = self.encoder_1(x)
coding = self.encoder_2(x)
x = self.decoder_1(coding)
rebuild = self.decoder_2(x)
return coding, rebuild
ae = AutoEncoder()
# 定义损失函数和优化器
loss_func = tf.losses.MeanSquaredError()
optimizer = tf.optimizers.Adam()
train_loss = tf.keras.metrics.Mean(name='train_loss')
@tf.function
def train_step(batch_data):
with tf.GradientTape() as tape:
coding, rebuild = ae(batch_data)
loss = loss_func(batch_data, rebuild)
gradients = tape.gradient(loss, ae.trainable_variables)
optimizer.apply_gradients(zip(gradients, ae.trainable_variables))
train_loss(loss)
EPOCHS = 5
for epoch in range(EPOCHS):
train_loss.reset_states()
for batch_data in data:
train_step(batch_data)
template = 'Epoch {}, Loss: {}'
print(template.format(epoch + 1, train_loss.result()))
sample = X[:5]
sample_coding, sample_rebuild = ae(sample)
print(sample.shape, sample_coding.shape, sample_rebuild.shape)
for i in range(5):
plt.subplot(2, 5, i + 1)
plt.plot(sample[i])
plt.subplot(2, 5, i + 5 + 1)
plt.plot(sample_rebuild[i])
plt.show()
参考资料
- 邱锡鹏. 神经网络与深度学习. 北京: 机械工业出版社, 2020.
- AE、DAE、SAE和VAE简介:https://www.cnblogs.com/jins-note/p/12883863.html
- 自编码器维基百科:https://en.wikipedia.org/wiki/Autoencoder