近邻算法
$\boldsymbol k$近邻算法原理
$k$近邻($k$-nearest neighbor, $k$NN)算法是一种常用的监督学习方法。其基本思想为:给定一组数据,基于某种距离度量找出训练集中与其最靠近的$k$个训练样本,然后基于这$k$个邻居的信息来进行预测。通常,在分类任务中可使用投票法,即选择$k$个样本中出现最多的类别标记作为预测结果;在回归任务中可使用平均法,即将$k$个样本的实值输出标记的平均值作为预测结果。该算法属于“惰性学习(lazy learning)”方法之一,没有显式的学习过程。相应的,那些在训练阶段就对样本进行学习处理的方法,称为“急切学习(eager learning)”。
$$ y=\arg\underset{c_j}\max \sum_{x_i\in{N_k(x)}}\mathbb I(y_i=c_j),i=1,2,\cdots,N;j=1,2,\cdots,K $$其中,$x_i$为实例特征向量,$y_i={c_1,c_2\cdots,c_k}$为实例的类别,$N$为实例总数,$N_k(x)$为$x$在训练集总最邻近的$k$个点,$\mathbb I$为指示函数。
$k$近邻算法的特殊情况是$k=1$的情形,称为最近邻算法。
$\boldsymbol k$近邻算法的参数
$k$近邻算法有三个基本的超参数(super parameter):距离度量、$k$值的选择以及分类决策规则的决定。
距离度量
$$ L_p(x_i,x_j)=(\sum_{l=1}^{n}|x_i^{(l)}-x_j^{(l)}|^p)^{\frac{1}{p}} $$在二维空间中的Minkowski距离的等距线示意图如下:
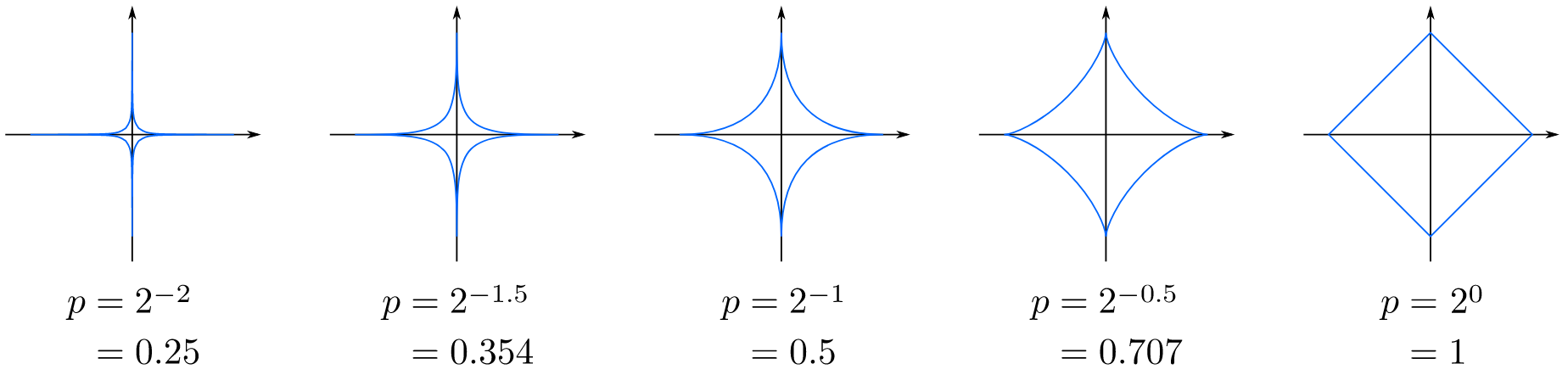
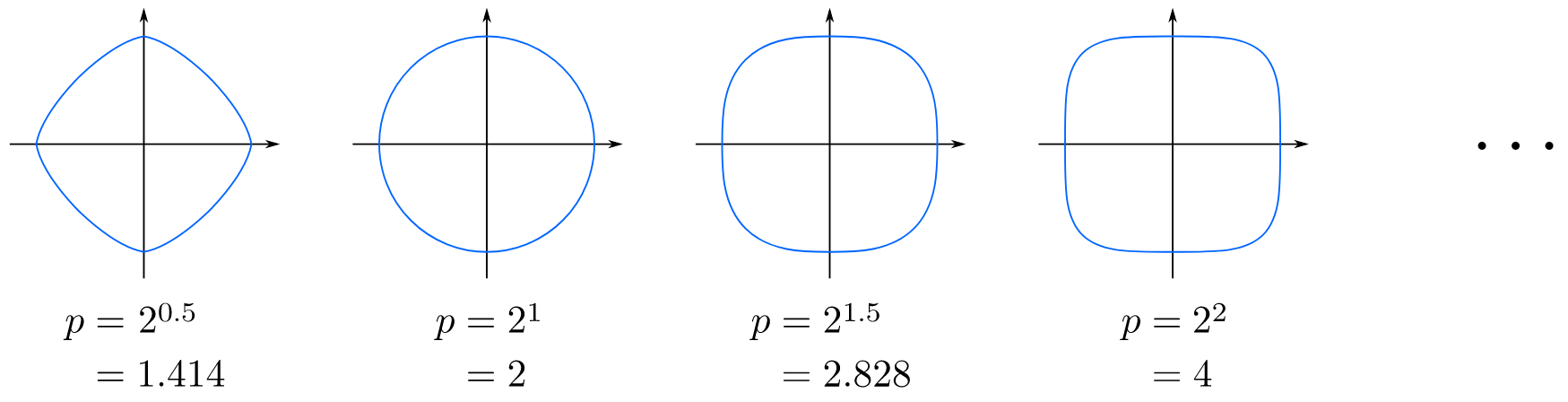
当$p=2$时,称为欧氏距离(Euclidean distance);当$p=1$时,称为曼哈顿距离(Manhattan distance)。不同的距离度量确定的最近邻点不同。
$\boldsymbol k$值的选择
$k$值的选择会对$k$近邻算法的结果产生重大影响。如果选择较小的$k$值,就相当于用较小的邻域中的训练实例进行预测,预测结果会对邻近的实例点非常敏感。如果邻近的实例点是噪声,预测就会出错。换句话说,$k$值的减小意味着整体模型变得复杂,容易发生过拟合。
如果选择较大的$k$值,就相当于用较大邻域中的训练实例进行预测,使模型变得简单。如果$k=N$,那么无论输入实例是什么,都将简单地预测它属于在训练实例中最多的类。这时,模型过于简单,完全忽略训练实例中的大量有用信息,是不可取的。通常$k$一般取一个较小的数值,通常采用交叉验证法来选取最优的$k$值。
分类决策规则
$k$近邻算法中的分类决策规则往往是多数表决,即由输入实例的$k$个近邻的训练实例中的多数类决定输入实例所属的类别。分类决策规则也可以按照距离加权,即赋予每个邻近实例点一个权重,距离给定实例更近的邻近点的权重更大。这样做考虑到了多数表决时距离带来的影响。
$\boldsymbol k\boldsymbol d$树
实现$k$近邻算法时,主要考虑的问题是如何对训练数据进行快速$k$近邻搜索。这点在特征空间维数大及训练数据容量大时尤为重要。
构造$\boldsymbol k \boldsymbol d$树
实现$k$近邻算法时,对数据集进行线性扫描是非常耗时的,$kd$树是一种高效的训练数据存储方式。$kd$树是二叉树,表示对$k$维空间的一个划分。构造$kd$树相当于用垂直于坐标轴的超平面将$k$维空间切分,构成一系列的$k$维超矩形区域。$kd$树的每个节点对应一个$k$维超矩形区域。
构造$kd$树的方法如下:构造根结点,使根结点对应于$k$维空间中包含所有实例点的超矩形区域。通过下面的递归方法,不断地对$k$维空间进行切分,生成子结点。在**超矩形区域(结点)**上选择一个坐标轴和在此坐标轴上的一个切分点,确定一个超平面,这个超平面通过选定的切分点并垂直于选定的坐标轴,将当前超矩形区域切分为左右两个子区域(子结点)。这时,实例被分到两个子区域。这个过程直到子区域内没有实例时终止。在此过程中,将实例保存在相应的结点上。
通常,依次选择坐标轴对空间切分,选择训练实例点在选定坐标轴上的中位数为切分点,这样得到的kd树是平衡的,但平衡的$kd$树搜索时的效率未必是最优的。
构造平衡$\boldsymbol k \boldsymbol d$树的算法:
输入:$k$维空间数据集$T={x_1,x_2,\cdots,x_N}$,其中$x_i=(x_i^{(1)},x_i^{(2)},\cdots,x_i^{(k)})^\text T,i=1,2,\cdots,N$。
输出:$kd$树。
(1) 开始:构造根结点,对应包含$T$的$k$维空间的超矩形区域。选择$x^{(1)}$为坐标轴,以T中所有实例$x^{(1)}$坐标的中位数为切分点,将根结点对应的超矩形区域切分为两个子区域。切分由通过切分点并与坐标轴$x^{(1)}$垂直的超平面实现。由根结点生成深度为1的左、右子结点:左子结点对应坐标$x^{(1)}$小于切分点的子区域,右子结点对应坐标$x^{(1)}$大于切分点的子区域。
将落在切分超平面上的实例点保存在根结点。
(2) 重复:对深度为$j$的结点,选择$x^{(l)}$为切分,$l=j(\text{mod}k)+1$,以该结点的区域中所有实例的$x^{(l)}$坐标的中位数为切分点,将该结点对应的超矩形区域划分为两个子区域。以此类推。
(3) 直到两个子区域没有实例存在时停止,从而形成$kd$树的区域划分。
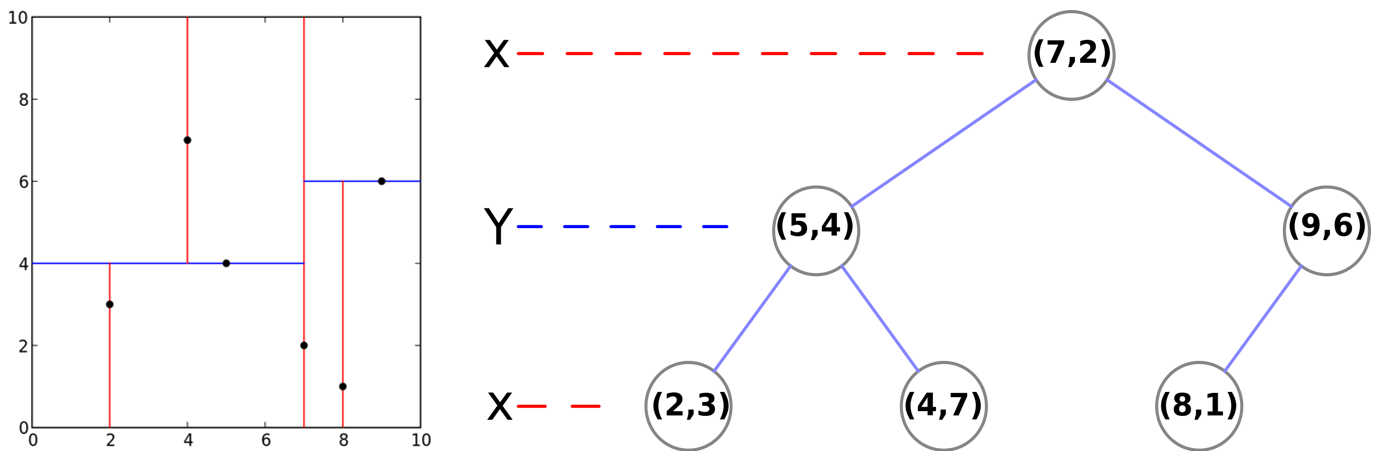
下图为构建$kd$树的实例。数据集为:$T={(2,3)^\text T,(5,4)^\text T,(9,6)^\text T,(4,7)^\text T,(8,1)^\text T,(7,2)^\text T}$。首先选择$x^{(1)}$轴(共两个维度,$x^{(1)}$即为第一个维度),6个数据点的$x^{(1)}$坐标的中位数是7(6是中位数,但是$x^{(1)}=6$上无数据点),以$x^{(1)}=7$将空间分为左右两个子矩形(子结点);接着,做矩形以$x^{(2)}=4$分为两个子矩形,右矩形以$x^{(2)}=6$分为两个子矩形,如此递归,最终得到如右图所示的$kd$树。
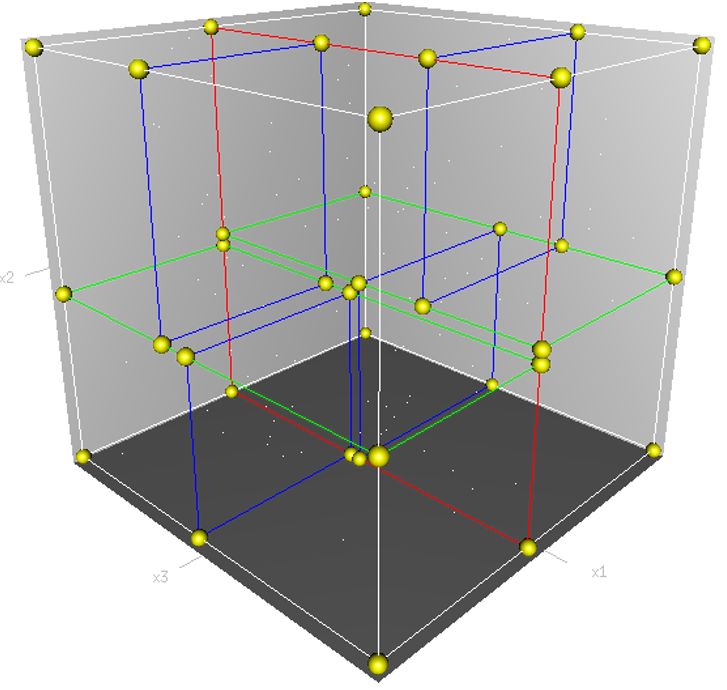
三维空间内$kd$树的构造如下所示:
搜索$\boldsymbol k \boldsymbol d$树
使用$kd$树可以减少搜索的计算量。以搜索最近邻为例:首先找到包含目标点的叶节点,然后从该结点出发,依次退回到父结点,不断查找与目标点最邻近的结点,当确定不可能存在更近的结点时终止。这样搜索就被限制在空间的局部区域上,效率大为提高。
包含目标点的叶结点对应包含目标点的最小超矩形区域。以此叶结点的实例点作为当前最近点。目标点的最近邻一定在以目标点为中心并通过当前最近点的超球体的内部。然后返回当前节点的父结点,如果父结点的另一子结点的超矩形区域与超球体相交,那么在相交的区域内寻找与目标点更近的实例点。如果存在这样的点,将此点作为新的当前最近点。算法转到更上一级的父结点,继续上述过程。若父结点的另一子结点的超矩形区域与超球体不相交,或不存在比当前最近点更近的点,则停止搜索。
使用$\boldsymbol k \boldsymbol d$树的最近邻搜索算法:
输入:已构造的$kd$树、目标点$x$。
输出:$x$的最近邻。
(1) 在$kd$树中找出包含目标点$x$的叶结点。从根结点出发,递归地向下访问$kd$树。若目标点$x$当前维的坐标小于切分点的坐标,则移动到左子结点,否则移动到右子结点。直到子结点为叶结点为止。
(2) 以此叶结点为当前最近点。
(3) 递归地向上回退,在每个结点进行以下操作:
如果该结点保存的实例点比当前最近点距目标点更近,则以该实例点为当前最近点。
当前最近点一定存在于该结点的一个子结点对应的区域。检查该子结点的父结点的另一子结点对应的区域是否有更近的点。具体地,检查另一子结点对应的区域是否与以目标点为球心、以目标点与当前最近点间的距离为半径的超球体相交。如果相交,可能在另一个子结点对应的区域内存在距离目标点更近的点,移动到另一子结点,接着,递归地搜索;如果不相交,向上回退。
(4) 当回退到根结点时,搜索结束。最后的“当前最近点”即为$x$的最近邻点。
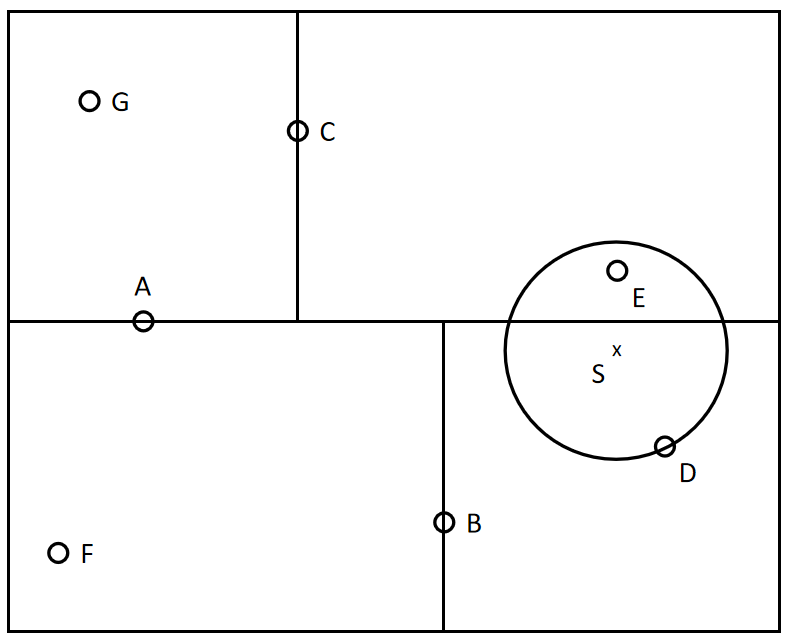
$kd$树搜索最近邻的示例如下所示。根结点为A,共有7个实例点;令有一个输入目标实例点S,求S的最近农林的过程如下:首先在$kd$树中找到包含S的叶结点D,以D点作为近似最近邻。真正最近邻一定在以点S为中心通过点D的元的内部。然后返回结点D的父结点B,在结点B的另一子结点F的区域内搜索最近邻。结点F的区域与圆不相交,不可能有最近邻点。继续返回上一级父结点A,在结点A的另一子结点C的区域内搜索最近邻。结点C的区域与圆相交;该区域在圆内的实例点有点E,点E比点D更近,称为新的最近邻近似。最后得到点E是点S的最近邻。
基于numpy的k近邻算法实现
import numpy as np
from collections import Counter
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.utils import shuffle
iris = datasets.load_iris() # 导入sklearn iris数据集
X, y = shuffle(iris.data, iris.target, random_state=13) # 打乱数据后的数据与标签
X = X.astype(np.float32) # 数据转换为float32格式
offset = int(X.shape[0] * 0.7) # 训练集与测试集的简单划分,训练-测试比例为7:3
X_train, y_train = X[:offset], y[:offset]
X_test, y_test = X[offset:], y[offset:]
y_train = y_train.reshape((-1, 1))
y_test = y_test.reshape((-1, 1))
print('X_train=', X_train.shape)
print('X_test=', X_test.shape)
print('y_train=', y_train.shape)
print('y_test=', y_test.shape)
# 定义欧氏距离
def compute_distances(X, X_train):
num_test = X.shape[0] # 测试实例样本量
num_train = X_train.shape[0] # 训练实例样本量
dists = np.zeros((num_test, num_train)) # 基于训练和测试维度的欧氏距离初始化
M = np.dot(X, X_train.T) # 测试样本与训练样本的矩阵点乘
te = np.square(X).sum(axis=1) # 测试样本矩阵平方
tr = np.square(X_train).sum(axis=1) # 训练样本矩阵平方
dists = np.sqrt(-2 * M + tr + np.matrix(te).T) # 计算欧式距离
return dists
dists = compute_distances(X_test, X_train)
plt.imshow(dists, interpolation='none')
plt.show()
# 定义预测函数
def predict_labels(y_train, dists, k=1):
num_test = dists.shape[0] # 测试样本量
y_pred = np.zeros(num_test) # 初始化测试集预测结果
for i in range(num_test):
closest_y = [] # 初始化最近邻列表
labels = y_train[np.argsort(dists[i, :])].flatten()
closest_y = labels[0:k] # 取最近的k个值
c = Counter(closest_y) # 对最近的k个值进行计数统计
y_pred[i] = c.most_common(1)[0][0] # 取计数最多的类别
return y_pred
# 测试集预测结果
y_test_pred = predict_labels(y_train, dists, k=1)
y_test_pred = y_test_pred.reshape((-1, 1))
# 找出预测正确的实例
num_correct = np.sum(y_test_pred == y_test)
# 计算准确率
accuracy = float(num_correct) / X_test.shape[0]
print('Got %d/%d correct=>accuracy:%f' % (num_correct, X_test.shape[0], accuracy))
# 5折交叉验证
num_folds = 5
k_choices = [1, 3, 5, 8, 10, 12, 15, 20, 50, 100] # 候选k值
X_train_folds = np.array_split(X_train, num_folds) # 训练数据划分
y_train_folds = np.array_split(y_train, num_folds) # 训练标签划分
k_to_accuracies = {}
# 遍历所有候选k值
for k in k_choices:
for fold in range(num_folds): # 五折遍历
# 对传入的训练集单独划出一个验证集作为测试集
validation_X_test = X_train_folds[fold]
validation_y_test = y_train_folds[fold]
temp_X_train = np.concatenate(X_train_folds[:fold] + X_train_folds[fold + 1:])
temp_y_train = np.concatenate(y_train_folds[:fold] + y_train_folds[fold + 1:])
# 计算距离
temp_dists = compute_distances(validation_X_test, temp_X_train)
temp_y_test_pred = predict_labels(temp_y_train, temp_dists, k=k)
temp_y_test_pred = temp_y_test_pred.reshape((-1, 1))
# 查看分类准确率
num_correct = np.sum(temp_y_test_pred == validation_y_test)
num_test = validation_X_test.shape[0]
accuracy = float(num_correct) / num_test
k_to_accuracies[k] = k_to_accuracies.get(k, []) + [accuracy]
# 打印不同 k 值不同折数下的分类准确率
for k in sorted(k_to_accuracies):
for accuracy in k_to_accuracies[k]:
print('k = %d, accuracy = %f' % (k, accuracy))
# 打印不同 k 值不同折数下的分类准确率
for k in k_choices:
accuracies = k_to_accuracies[k] # 取出第k个k值的分类准确率
plt.scatter([k] * len(accuracies), accuracies) # 绘制不同k值准确率的散点图
accuracies_mean = np.array([np.mean(v) for k, v in sorted(k_to_accuracies.items())])
accuracies_std = np.array([np.std(v) for k, v in sorted(k_to_accuracies.items())])
plt.errorbar(k_choices, accuracies_mean, yerr=accuracies_std)
plt.title('Cross-validation on k')
plt.xlabel('k')
plt.ylabel('Cross-validation accuracy')
plt.show()
使用scikit-learn中的k近邻算法对鸢尾花数据进行分类
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
def plot_decision_boundary(model, axis):
"""
在axis范围内绘制模型model的决策边界
:param model: classification model which must have 'predict' function
:param axis: [left, right, down, up]
"""
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D', '#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
X, y = load_iris(return_X_y=True)
X = X[:, :2] # 仅选择前两个特征,便于绘制决策边界
X_train, X_test, y_train, y_test = train_test_split(X, y) # 将数据划分为训练集和测试集
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape) # (112, 2) (38, 2) (112,) (38,)
for i, n in enumerate([1, 5, 30]):
plt.subplot(1, 3, i + 1)
knn_cls = KNeighborsClassifier(n_neighbors=n)
knn_cls.fit(X_train, y_train)
y_pred = knn_cls.predict(X_test)
print(classification_report(y_test, y_pred)) # 分类报告中包含precision/recall/f1-score
plt.title('n_neighbors=' + str(n))
plot_decision_boundary(knn_cls, axis=[3, 8, 1, 5])
plt.scatter(X_test[y_test == 0, 0], X_test[y_test == 0, 1])
plt.scatter(X_test[y_test == 1, 0], X_test[y_test == 1, 1])
plt.scatter(X_test[y_test == 2, 0], X_test[y_test == 2, 1])
plt.show()
参考资料
- 李航. 统计学习方法. 北京: 清华大学出版社, 2019.
- 鲁伟. 机器学习: 公式推导与代码实现. 北京: 人民邮电出版社, 2022.
- Stanford University机器学习笔记:https://stanford.edu/~shervine/teaching/
- Minkowski距离维基百科:https://en.wikipedia.org/wiki/Minkowski_distance
- KD树维基百科https://en.wikipedia.org/wiki/K-d_tree