数学优化
(最小化);或者$f(\boldsymbol{x}^{*}) \geqslant f(\boldsymbol{x})$(最大化),其中$\mathcal D$为变量$\boldsymbol x$的约束集,也叫可行域;$\mathcal D$中的变量被称为可行解。
数学优化的类型
离散优化和连续优化
离散优化(discrete optimization)问题是目标函数的输入变量为离散变量,比如为整数或有限集合中的元素。离散优化问题主要有两个分支:
(1) 组合优化(combinatorial optimization):其目标是从一个有限集合中找出使得目标函数最优的元素。在一般的组合优化问题中,集合中的元素之间存在一定的关联,可以表示为图结构。典型的组合优化问题有旅行商问题、最小生成树问题、图着色问题等。很多机器学习问题都是组合优化问题,比如特征选择、聚类问题、超参数优化问题以及结构化学习(structured learning)中标签预测问题等。
(2) 整数规划(integer programming):输入变量$\boldsymbol x \in \mathbb Z^d$是一个整数向量。常见的整数规划问题通常为整数线性规划。整数线性规划的一种最直接的求解方法是:1. 去掉输入必须为整数的限制,将原问题转换为一般的线性规划问题,这个线性规划问题为原问题的松弛问题;2. 求得相应松弛问题的解;3. 把松弛问题的解四舍五入到最接近的整数。但是这种方法得到的解一般都不是最优的,因为原问题的最优解不一定在松弛问题最优解的附近。另外,这种方法得到的解也不一定满足约束条件。
离散优化问题的求解一般都比较困难,优化算法的复杂度都比较高。
连续优化(continuous optimization)目标函数的输入变量为连续变量$\boldsymbol x \in \mathbb R^d$,即目标函数为实函数。机器学习中的优化问题主要是连续优化问题。
无约束优化和约束优化
在连续优化问题中,根据是否有变量的约束条件,可以将优化问题分为无约束优化问题和约束优化问题。
$$ \min _{\boldsymbol{x}} \ \ f(\boldsymbol{x}) $$其中$\boldsymbol x \in \mathbb R^d$为输入变量,$f:\mathbb R \rightarrow \mathbb R $为目标函数。
约束优化(constrained optimization) 问题中变量$ \boldsymbol x $需要满足一些等式或不等式的约束。约束优化问题通常使用拉格朗日乘数法来进行求解。
线性优化和非线性优化
若目标函数和所有的约束函数都为线性函数,则该问题称为线性规划(linear programming)问题。相反,如果木变函数或任何一个约束函数为非线性函数,则该问题为 非线性规划(nonlinear programming)问题。
$$ f(\alpha \boldsymbol{x}+(1-\alpha) \boldsymbol{y}) \leq \alpha f(\boldsymbol{x})+(1-\alpha) f(\boldsymbol{y}), \ \ \forall \alpha \in[0,1] $$凸优化问题是一种特殊的约束优化问题,需满足目标函数为凸函数,并且等式约束函数为线性函数,不等式约束函数为凸函数。
凸优化基础
凸集
对于集合$C$,如果对任意$x,y \in C,\theta \in \mathbb R,0 \leqslant \theta \leqslant 1$,有$\theta x + (1-\theta)y \in C$,则集合$C$为凸集(convex set)。下图中,左边为凸集,右边为非凸集:
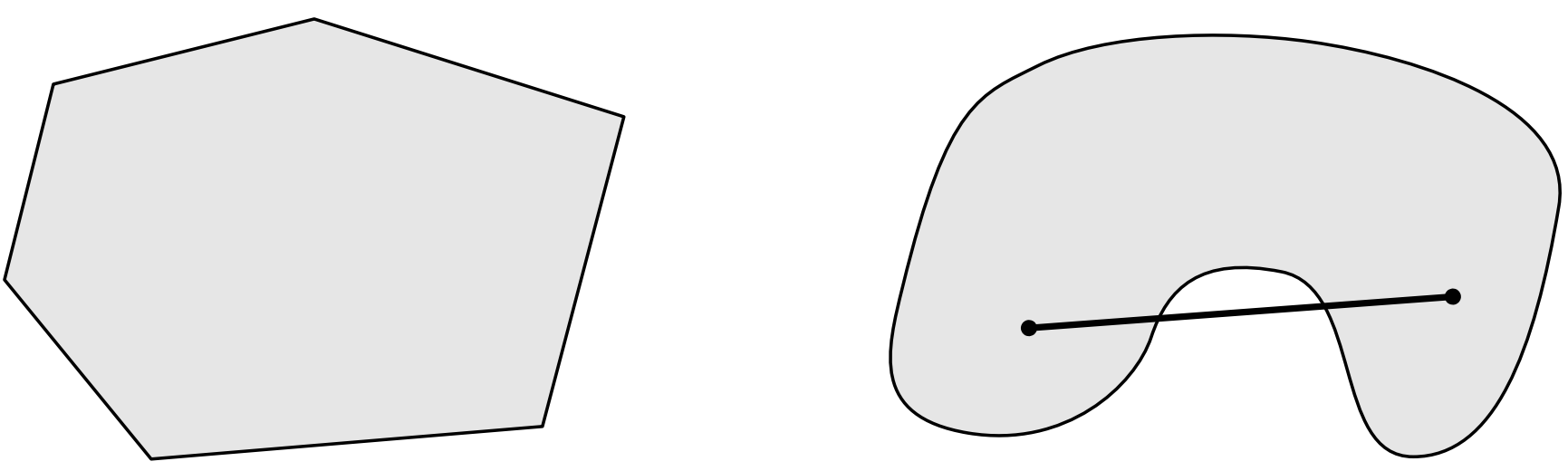
$\theta x+(1-\theta)y$称为点$x$和$y$的凸组合。凸集有以下实例:


凸函数
若函数$f:\mathbb R^n \rightarrow \mathbb R$为凸函数(convex function),则其定义域$\mathcal D(f)$为凸集,且对所有$x,y \in \mathcal D(f),\theta \in [0,1]$,有$f(\theta x+(1-\theta) y) \leqslant \theta f(x)+(1-\theta) f(y)$。
若函数$f$为凸函数,则$-f$为凹函数(concave function)。若上式中$x \not = y$且$\theta \in (0,1)$,则称函数$f$为严格凸的。
Jensen不等式
$$ f\left(\sum_{i=1}^{k} \theta_{i} x_{i}\right) \leqslant \sum_{i=1}^{k} \theta_{i} f(x_{i}) \text { for } \sum_{i=1}^{k} \theta_{i}=1, \theta_{i} \geqslant 0 \ \ \forall i $$$$ f\left(\int p(x) x d x\right) \leqslant \int p(x) f(x) d x \text { for } \int p(x) dx=1, p(x) \geqslant 0 \ \ \forall x $$$$ f(\mathbb{E}[x]) \leqslant \mathbb{E}[f(x)] $$上式被称为Jensen不等式(Jensen inequality)。
优化算法
优化问题一般都是通过迭代的方式来求解,即通过猜测一个初始的估计,然后不断迭代产生新的估计,最终收敛到期望的最优解。一个好的优化算法应该能在一定的时间或空间复杂度下能够快速准确地找到最优解。同时,好的优化算法受初始猜测点的影响较小,通过迭代能稳定地找到最优解的邻域,然后迅速收敛于最优解。
全局最优和局部最优
$$\boldsymbol x^*$$$$f(\boldsymbol X^*) \leqslant f(\boldsymbol X)$$$$\boldsymbol x^*$$的附近区域内,所有的函数值都会大于或者等于$f(\boldsymbol x^*)$。
对于所有的$\boldsymbol x \in A$,都有$f(\boldsymbol X^) \leqslant f(\boldsymbol X)$成立,则$\boldsymbol X^$为全局最小值,或全局最优解。求局部最优解一般是比较容易的,但很难保证其为全局最优解。对于线性规划或凸优化问题,局部最优解就是全局最优解。
$$\boldsymbol x^*$$$$f(\boldsymbol x)$$是二次连续可微的,我们可以通过检查目标函数在点$\boldsymbol x^$的梯度$\nabla f\left(\boldsymbol{x}^{}\right)$和Hessian矩阵$\nabla^2f(\boldsymbol x^*)$来判断。
$$\boldsymbol x^*$$$$\nabla f\left(\boldsymbol{x}^{*}\right)=0$$。
$$\boldsymbol x^*$$$$\boldsymbol x^*$$$$\nabla f\left(\boldsymbol{x}^{*}\right)=0$$$$\nabla^2f(\boldsymbol x^*)$$为半正定矩阵。
梯度下降法
梯度下降法(gradient descent method)经常用来求解无约束优化的极小值问题。对于函数$f(\boldsymbol x)$,如果$f(\boldsymbol x)$在点$\boldsymbol x_t$附近是连续可微的,那么$f(\boldsymbol x)$下降最快的方向是$f(\boldsymbol x)$在点$\boldsymbol x_t$梯度方向的反方向。
$$\boldsymbol{x}_{t+1}=\boldsymbol{x}_{t}-\alpha_{t} \nabla f\left(\boldsymbol{x}_{t}\right), t \geqslant 0$$$$ f(\boldsymbol{x}_{0}) \geqslant f(\boldsymbol{x}_{1}) \geqslant f(\boldsymbol{x}_{2}) \geqslant \cdots $$如果顺利的话,序列$(\boldsymbol x_n)$收敛到局部最优解$\boldsymbol x^*$。注意,每次迭代步长$\alpha$可以改变,但其值必须合适,如果过大就不会收敛,如果过小则收敛速度太慢。
梯度下降法的过程如下图所示:
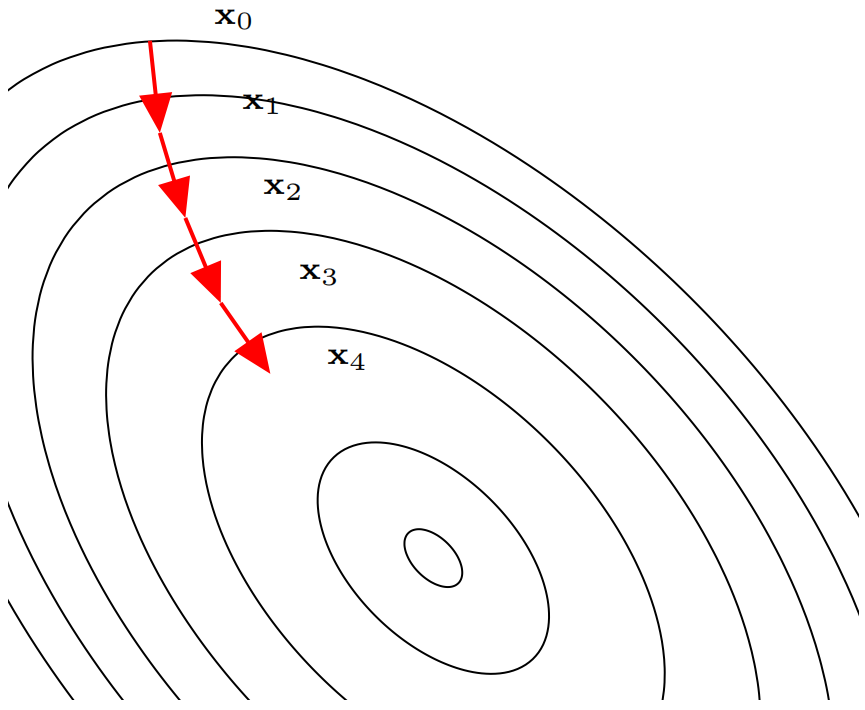
梯度下降法为一阶收敛算法,当靠近极小值时梯度变小,收敛速度会变慢,并且可能以“之字形”的方式下降。如果目标函数为二阶连续可微,我们可以采用牛顿法。牛顿法为二阶收敛算法,收敛速度更快,但是每次迭代需要计算Hessian矩阵的逆矩阵,复杂度较高。
相反,如果我们要求解一个最大值问题,就需要向梯度正方向迭代进行搜索,逐渐接近函数的局部极大值点,这个过程则被称为梯度上升法(gradient ascent method)。
# numpy实现梯度下降算法逼近一个函数的最小值
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-80, 80, 5000)
def f(x):
# 目标函数
return x ** 2 + 5 * x + 2
def df(x):
# 目标函数的导数
return 2 * x + 5
alpha = 0.1 # 学习率
plt.plot(x, f(x))
init_x = 76 # x的初始值
init_value = f(init_x)
last_x = init_x
last_value = init_value
xs = [init_x]
values = [init_value]
# 10000次迭代
for i in range(10000):
now_x = last_x - alpha * df(last_x)
now_value = f(now_x)
if abs(now_value - last_value) < 1e-8: # 当某一步优化进行不明显时,终止优化
break
last_x = now_x
last_value = now_value
print('The {}th step, x={}, f(x)={}'.format(i + 1, last_x, last_value))
xs.append(last_x)
values.append(last_value)
plt.plot(xs, values, color='red')
plt.show()
拉格朗日乘数法与KKT条件
$$ \begin{aligned} & \min_{\boldsymbol x} \ \ f(x)\\ & \text{subject to} \ \ h_i(\boldsymbol x)=0,i=1,\cdots,m;g_j(\boldsymbol x) \leqslant 0,j=1,\cdots,n \end{aligned} $$$$ \mathcal{D}=\operatorname{dom}(f) \cap \bigcap_{i=1}^{m} \operatorname{dom}\left(h_{i}\right) \cap \bigcap_{j=1}^{n} \operatorname{dom}\left(g_{j}\right) \subseteq \mathbb{R}^{d} $$其中$\operatorname{dom}(f)$是函数$f$的定义域。
等式约束优化问题
$$ \Lambda(\boldsymbol{x}, \lambda)=f(\boldsymbol{x})+\sum_{i=1}^{m} \lambda_{i} h_{i}(\boldsymbol{x}) $$$$f(\boldsymbol x^*)$$$$ \nabla f(\boldsymbol{x})+\sum_{i=1}^{m} \lambda_{i} \nabla h_{i}(\boldsymbol{x})=0, \ \ h_i(\boldsymbol x)=0,i=0,\cdots,m $$上面方程组的解即为原始问题的可能解。在实际应用中,需根据问题来验证是否为极值点。
拉格朗日乘数法是将一个有$d$个变量和$m$个等式约束条件的最优化问题转换为一个有$d+m$个变量的函数求平稳点的问题。拉格朗日乘数法所得的平稳点会包含原问题的所有极值点,但并不保证每个平稳点都是原问题的极值点。
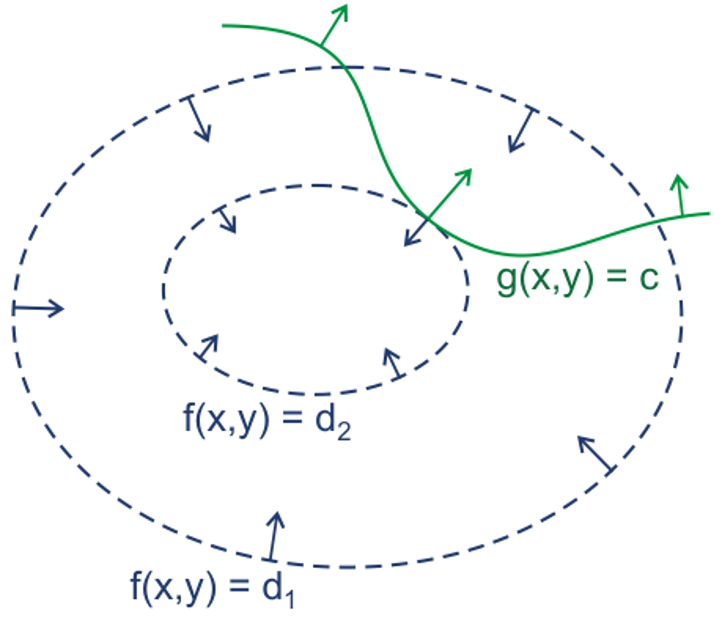
等式约束优化问题的解释如下:假设目标函数是二维的,即$f(x,y)$,下图蓝色虚线为目标函数的等高线图。对于凸的目标函数,只有当等高线与目标函数的曲线相切时才有可能得到可行解。因此在最优解处目标函数与约束函数$g(x,y)$相切,这时两者的法向量是平行的,即:$\nabla f(x,y)+\lambda \nabla g(x,y)=0$,与上文对应。
不等式约束优化问题
$$ \Lambda(\boldsymbol{x}, \boldsymbol{a}, \boldsymbol{b})=f(\boldsymbol{x})+\sum_{i=1}^{m} a_{i} h_{i}(\boldsymbol{x})+\sum_{j=1}^{n} b_{j} g_{j}(\boldsymbol{x}) $$其中$h_i(x)$为第$i$个等式约束,$g_j(x)$为第$j$个不等式约束($\leqslant$),$\boldsymbol a=[a_1,\cdots,a_m]^\text{T}$为等式约束的拉格朗日乘数,$\boldsymbol b=[b_1,\cdots,b_n]^\text{T}$为不等式约束的拉格朗日乘数,$b_i \geqslant 0$。
$$ \begin{aligned} \min _{\boldsymbol{x}} \max _{\boldsymbol{a}, \boldsymbol{b}} \ \ \ & \Lambda(\boldsymbol{x}, \boldsymbol{a}, \boldsymbol{b}) \\ \text { subject to} \ \ \ & \boldsymbol{b} \geqslant 0 \end{aligned} $$这个min-max优化问题称为主问题(primal problem)。
$$ \Gamma(\boldsymbol{a}, \boldsymbol{b})=\min _{\boldsymbol{x} \in \mathcal{D}} \Lambda(\boldsymbol{x}, \boldsymbol{a}, \boldsymbol{b}) $$$$ \Gamma(\boldsymbol{a}, \boldsymbol{b})=\min _{\boldsymbol{x} \in \mathcal{D}} \Lambda(\boldsymbol{x}, \boldsymbol{a}, \boldsymbol{b}) \leqslant \Lambda(\tilde{\boldsymbol{x}}, \boldsymbol{a}, \boldsymbol{b}) \leqslant f(\tilde{\boldsymbol{x}}) $$$$ \begin{aligned} \max _{\boldsymbol{a}, \boldsymbol{b}} \ \ \ & \Gamma(\boldsymbol{a}, \boldsymbol{b}) \\ \text {subject to} \ \ \ & \boldsymbol{b} \geqslant 0 \end{aligned} $$拉格朗日对偶函数为凸函数,因此拉格朗日对偶问题为凸优化问题。
$$d^* $$$$d^* \leqslant p^*$$,这个性质称为弱对偶性(weak duality)。如果$d^* = p^*$,这个性质称为强对偶性(strong duality)。
$$ \begin{aligned} \nabla f\left(\boldsymbol{x}^{*}\right) +\sum_{i=1}^{m} a_{i}^{*} \nabla h_{i}(\boldsymbol{x}^{*})&+\sum_{j=1}^{n} b_{j}^{*} \nabla g_{j}(\boldsymbol{x}^{*})=0 \\ h_{i}(\boldsymbol{x}^{*})=0, \ \ & i=0, \cdots, m \\ g_{j}(\boldsymbol{x}^{*}) \leqslant 0, \ \ & j=0, \cdots, n \\ b_{j}^{*} g_{j}\left(\boldsymbol{x}^{*}\right)=0, \ \ & j=0, \cdots, n \\ b_{j}^{*} \geqslant 0, \ \ & j=0, \cdots, n \end{aligned} $$称为不等式约束优化问题的KKT条件(Karush-Kuhn-Tucker condition)。KKT条件是拉格朗日乘数法在不等式约束优化问题上的泛化。当原问题是凸优化问题时,满足KKT条件的解也是原问题和对偶问题的最优解。
KKT条件中第四个式子称为互补松弛(complementary slackness)条件。如果最优解$\boldsymbol x^* $出现在不等式约束的边界上$g_j(\boldsymbol x)=0$,则$b_j^* >0$;如果最优解$\boldsymbol x$出现在不等式约束的内部$g_j(\boldsymbol x)<0$,则$b_j^*=0$。互补松弛条件说明当最优解出现在不等式约束的内部,则约束失败。
# cvxpy解决凸优化问题
import cvxpy as cvx
# 定义要被优化的变量
x = cvx.Variable()
y = cvx.Variable()
# 定义约束,可以包含等式约束和不等式约束
constraints = [x + y == 1, x - y >= 1]
# 定义优化目标
obj = cvx.Minimize((x - y) ** 2)
# 将优化目标和约束组成优化问题
prob = cvx.Problem(obj, constraints)
# 求解
prob.solve()
print("status: ", prob.status) # optimal
print("optimal value: ", prob.value) # 1.0
print("optimal variables: ", x.value, y.value) # 1.0 1.570086213240983e-22
参考资料
-
李航. 统计学习方法. 北京: 清华大学出版社, 2019.
-
邱锡鹏. 神经网络与深度学习. 北京: 机械工业出版社, 2020.
-
Stanford University机器学习课程:http://cs229.stanford.edu/
-
cvxpy官方网站:https://www.cvxpy.org/