支持向量机
线性支持向量机与硬间隔最大化
支持向量机(support vector machine, SVM) 是一个经典的机器学习二分类算法,其找到的分割超平面具有更好的鲁棒性,因此广泛使用在很多任务上,并表现出了很强的优势。
给定一个二分类数据集$\mathcal{D}={(\boldsymbol{x}^{(n)}, y^{(n)})}_{n=1}^{N}$,其中$y_n \in {+1,-1}$,如果两类样本是线性可分的,即存在一个超平面$\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+b=0$将两类样本分开,对于每一类样本都有$y^{(n)}(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}^{(n)}+b)>0$。
$$ \gamma^{(n)}=\frac{\|\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}^{(n)}+b\|}{\|\boldsymbol{w}\|}=\frac{y^{(n)}(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}^{(n)}+b)}{\|\boldsymbol{w}\|} $$$$ \gamma=\min _{n} \gamma^{(n)} $$$$ \begin{aligned} \underset{\boldsymbol{w}, b}\max \ \ & \gamma \\ \text { s.t. } \ \ & \frac{y^{(n)}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}^{(n)}+b\right)}{\|\boldsymbol{w}\|} \geq \gamma, \forall n \end{aligned} $$$$ \begin{aligned} \underset{\boldsymbol{w}, b}\max \ \ & \frac{1}{\|\boldsymbol w\|} \\ \text { s.t. } \ \ & {y^{(n)}(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}^{(n)}+b)} \geq 1, \forall n \end{aligned} $$$$ \begin{aligned} \underset{\boldsymbol{w}, b}\min \ \ & \frac{1}{2}\|\boldsymbol w\|^2 \\ \text { s.t. } \ \ & {y^{(n)}(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}^{(n)}+b)} \geq 1, \forall n \end{aligned} $$这就是支持向量机的基本型。下图展示了分割超平面、支持向量以及间隔之间的关系。
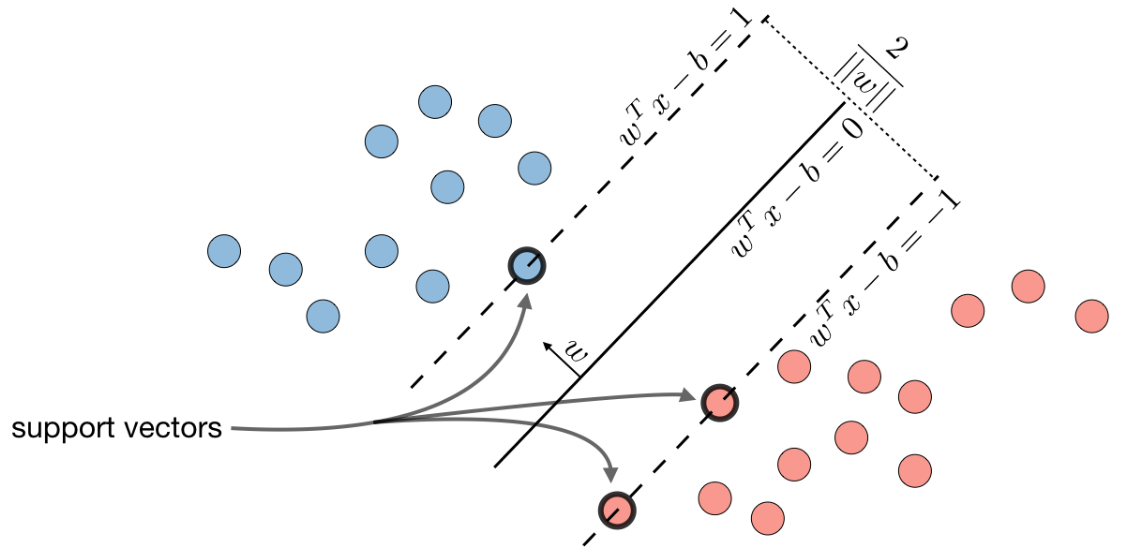
支持向量机的主优化问题为凸优化问题,满足强对偶性,可以通过多种凸优化方法来进行求解,得到拉格朗日乘数的最优值$\lambda^*$。但由于其约束条件的数量为训练样本数量,一般的优化方法代价比较高,因此在实践中通常采用比较高效的优化算法,比如**序列最小优化(sequential minimal optimization, SMO)**算法。
在计算出$\lambda^$后,可以计算出最优权重$\boldsymbol w^$,最优偏置$b^*$可以通过任选一个支持向量计算得到。
$$ f(\boldsymbol{x})=\operatorname{sgn}(\boldsymbol{w}^{* \mathrm{T}} \boldsymbol{x}+b^{*})=\operatorname{sgn}\left(\sum_{n=1}^{N} \lambda_{n}^{*} y^{(n)}(\boldsymbol{x}^{(n)})^{\mathrm{T}} \boldsymbol{x}+b^{*}\right) $$线性支持向量机与软间隔最大化
$$ \begin{aligned} \min _{\boldsymbol{w}, b}\ \ & \frac{1}{2}\|\boldsymbol{w}\|^{2}+C \sum_{n=1}^{N} \xi_{n} \\ \text { s.t. } \ \ & 1-y^{(n)}(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}^{(n)}+b)-\xi_{n} \leq 0,\ \ \forall n\\ & \xi_{n} \geq 0,\ \ \forall n \end{aligned} $$$$ \min _{\boldsymbol{w}, b} \sum_{n=1}^{N} \max (0,1-y^{(n)}(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}^{(n)}+b))+\frac{1}{C} \cdot \frac{1}{2}\|\boldsymbol{w}\|^{2} $$其中,$\max (0,1-y^{(n)}(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}^{(n)}+b))$称为Hinge损失函数。
非线性支持向量机与核函数
在前面的讨论中,我们假设训练样本是线性可分的。然而在现实任务中,原始样本空间内也许并不存在一个能正确划分两类样本的超平面,比如**“异或”问题**。
对于这类问题,可以通过一个非线性变换,即核技巧(kernel trick),将输入空间映射到更高维的特征空间,使得样本在这个高维特征空间内线性可分。幸运的是,如果原始空间是有限维,即属性数有限,那么一定存在一个高维特征空间使样本可分。
令$\phi(\boldsymbol x)$表示将$\boldsymbol x$映射后的特征向量,于是,在特征空间中划分超平面所对应的模型可表示为$f(\boldsymbol x)=\boldsymbol w^\text T \phi(\boldsymbol x)+b$,其中$\boldsymbol w$和$b$是模型参数,因此原始问题形式只需将$\boldsymbol x$变为$\phi(\boldsymbol x)$即可。
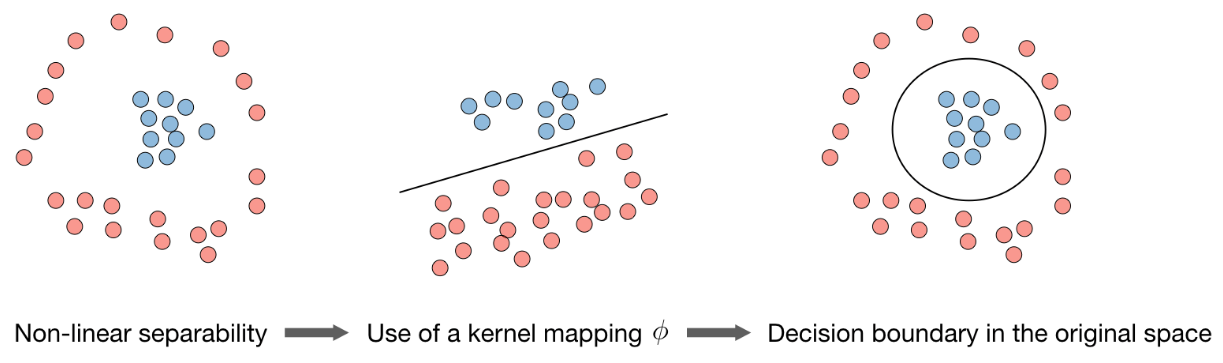
其中$K(\boldsymbol x,\boldsymbol z)=\phi(\boldsymbol x)^\text T \phi(\boldsymbol z)$为核函数。通常我们不需要显式地给出$\phi(\boldsymbol x)$的具体形式,可以通过核技巧来构造。例如以$\boldsymbol x,\boldsymbol z \in \mathbb R^2$为例,可以构造一个核函数$K(\boldsymbol{x}, \boldsymbol{z})=\left(1+\boldsymbol{x}^{\mathrm{T}} \boldsymbol{z}\right)^{2}=\phi(\boldsymbol{x})^{\mathrm{T}} \phi(\boldsymbol{z})$来隐式地计算$\boldsymbol x,\boldsymbol z$在特征空间$\phi$中的内积,其中$\phi(\boldsymbol{x})=\left[1, \sqrt{2} x_{1}, \sqrt{2} x_{2}, \sqrt{2} x_{1} x_{2}, x_{1}^{2}, x_{2}^{2}\right]^{\mathrm{T}}$。
线性可分支持向量机的算法实现
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
from cvxopt import matrix, solvers # 凸优化求解库
from sklearn.metrics import accuracy_score
# 生成模拟二分类数据集
X, y = make_blobs(n_samples=150, n_features=2, centers=2, cluster_std=1.2, random_state=40)
colors = {0: 'r', 1: 'g'}
plt.scatter(X[:, 0], X[:, 1], marker='o', c=pd.Series(y).map(colors))
plt.show()
# 将标签转换为1/-1
y_ = y.copy()
y_[y_ == 0] = -1
y_ = y_.astype(float)
X_train, X_test, y_train, y_test = train_test_split(X, y_, test_size=0.3, random_state=43)
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
# cvxopt库的使用示例
# 1. 定义二次规划参数
P = matrix([[1.0, 0.0], [0.0, 0.0]])
q = matrix([3.0, 4.0])
G = matrix([[-1.0, 0.0, -1.0, 2.0, 3.0], [0.0, -1.0, -3.0, 5.0, 4.0]])
h = matrix([0.0, 0.0, -15.0, 100.0, 80.0])
# 2. 构建求解
sol = solvers.qp(P, q, G, h)
# 3. 获取最优值
print(sol['x'], sol['primal objective'])
# 实现线性可分支持向量机
class Hard_Margin_SVM:
# 线性可分支持向量机拟合方法
def fit(self, X, y):
# 训练样本数和特征数
m, n = X.shape
# 初始化二次规划相关变量:P/q/G/h
self.P = matrix(np.identity(n + 1, dtype=np.float))
self.q = matrix(np.zeros((n + 1,), dtype=np.float))
self.G = matrix(np.zeros((m, n + 1), dtype=np.float))
self.h = -matrix(np.ones((m,), dtype=np.float))
# 将数据转为变量
self.P[0, 0] = 0
for i in range(m):
self.G[i, 0] = -y[i]
self.G[i, 1:] = -X[i, :] * y[i]
sol = solvers.qp(self.P, self.q, self.G, self.h) # 构建二次规划求解
# 对权重和偏置寻优
self.w = np.zeros(n, )
self.b = sol['x'][0]
for i in range(1, n + 1):
self.w[i - 1] = sol['x'][i]
return self.w, self.b
# 定义模型预测函数
def predict(self, X):
return np.sign(np.dot(self.w, X.T) + self.b)
hard_margin_svm = Hard_Margin_SVM() # 创建线性可分支持向量机模型实例
hard_margin_svm.fit(X_train, y_train) # 执行训练
y_pred = hard_margin_svm.predict(X_test) # 模型预测
print(accuracy_score(y_test, y_pred)) # 计算测试集准确率
使用scikit-learn中的支持向量机算法对鸢尾花数据进行分类
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC, LinearSVC
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
def plot_decision_boundary(model, axis):
"""
在axis范围内绘制模型model的决策边界
:param model: classification model which must have 'predict' function
:param axis: [left, right, down, up]
"""
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A', '#FFF59D', '#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
X, y = load_iris(return_X_y=True)
X = X[:, :2] # 仅选择前两个特征,便于绘制决策边界
X_train, X_test, y_train, y_test = train_test_split(X, y)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape) # (112, 2) (38, 2) (112,) (38,)
lin_svc = LinearSVC()
lin_svc.fit(X_train, y_train)
print('classification accuracy of LinearSVC: ', lin_svc.score(X_test, y_test))
svc_rf = SVC(kernel='rbf', degree=5)
svc_rf.fit(X_train, y_train)
print('classification accuracy of SVC with RBF kernel: ', svc_rf.score(X_test, y_test))
plt.subplot(1, 2, 1)
plot_decision_boundary(lin_svc, axis=[3, 8, 1, 5])
plt.scatter(X_test[y_test == 0, 0], X_test[y_test == 0, 1])
plt.scatter(X_test[y_test == 1, 0], X_test[y_test == 1, 1])
plt.scatter(X_test[y_test == 2, 0], X_test[y_test == 2, 1])
plt.subplot(1, 2, 2)
plot_decision_boundary(svc_rf, axis=[3, 8, 1, 5])
plt.scatter(X_test[y_test == 0, 0], X_test[y_test == 0, 1])
plt.scatter(X_test[y_test == 1, 0], X_test[y_test == 1, 1])
plt.scatter(X_test[y_test == 2, 0], X_test[y_test == 2, 1])
plt.show()
参考资料
- 周志华. 机器学习. 北京: 清华大学出版社, 2016.
- 邱锡鹏. 神经网络与深度学习. 北京: 机械工业出版社, 2020.
- 鲁伟. 机器学习:公式推导与代码实现. 北京: 人民邮电出版社, 2022.
- Stanford University机器学习笔记:https://stanford.edu/~shervine/teaching/